EigenInsight - Enterprise Knowledge Intelligence Platform

Project Overview
EigenInsight is an enterprise knowledge intelligence product for teams that need trustworthy AI over private documents, customer data, and external research sources.
It connects knowledge base ingestion, multimodal understanding, vector retrieval, citation-aware answers, company research, CRM workflows, and long-running agent tasks in one operational product.
Product Positioning
EigenInsight is designed for enterprise knowledge operations rather than casual chat. It gives teams a way to turn scattered files, records, and public information into searchable, citable, permission-aware intelligence.
- Upload, parse, index, and search enterprise documents
- Understand multimodal materials including PDFs, reports, images, and screenshots
- Return traceable answers with source citations and audit paths
- Automate customer and company research
- Support CRM writeback, team permissions, and reusable memory spaces
Core Modules
The product combines three major workflows: knowledge retrieval, structured business research, and action-oriented automation.
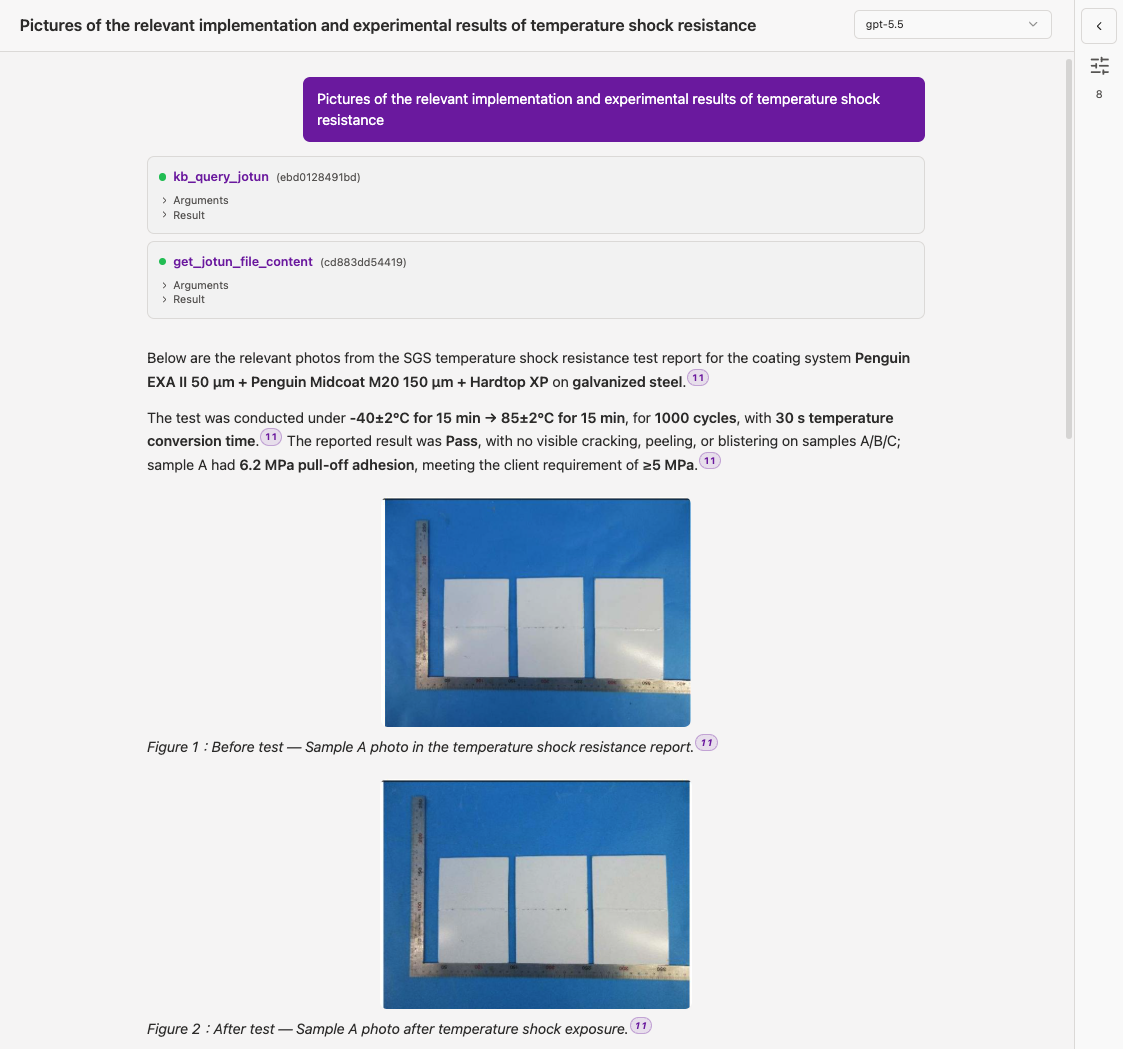
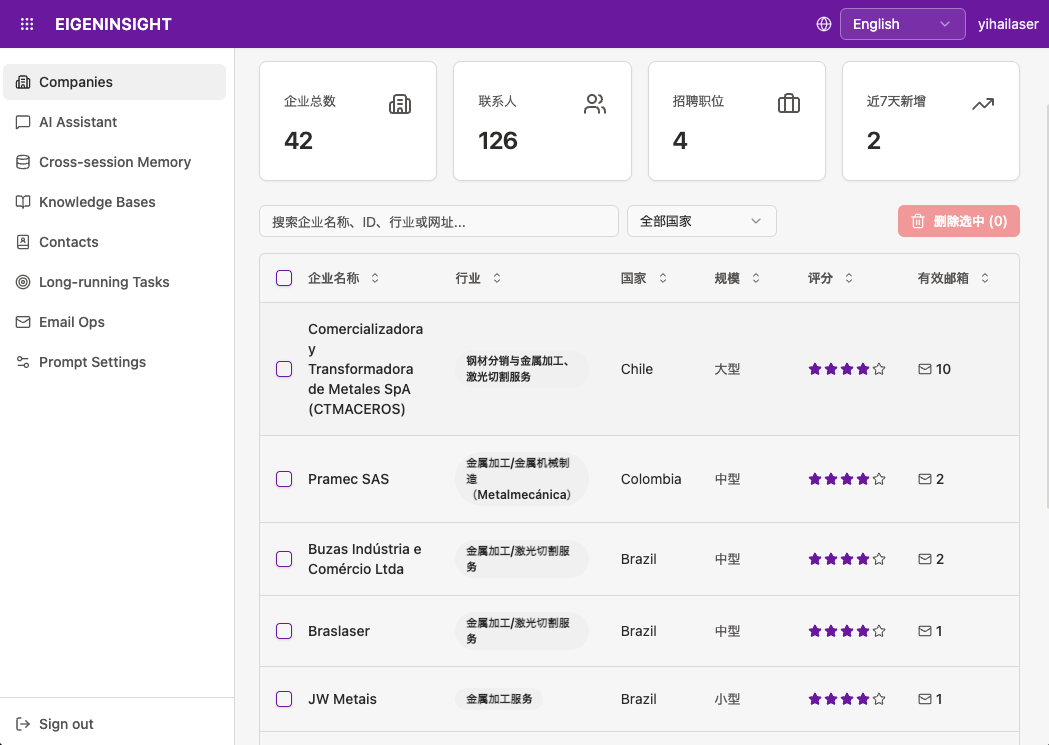
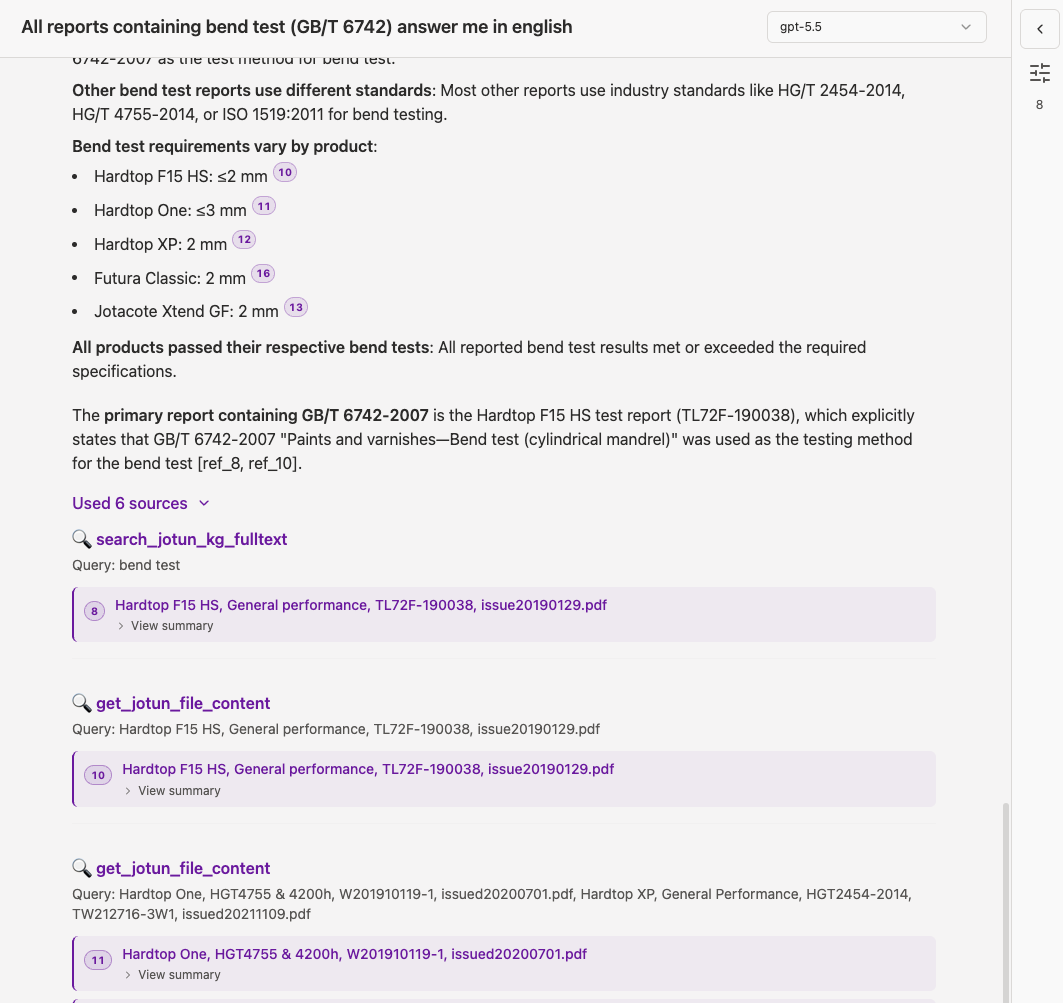
Technical Foundation
EigenInsight uses a modern AI application stack: Next.js on the frontend, LangServe and LangGraph for agent workflows, knowledge graph services, PostgreSQL with vector capabilities, Qdrant, and object storage such as S3 or GCS.
The system is built around production enterprise requirements:
- Private knowledge ingestion and indexing
- Source-grounded retrieval and citation control
- Long-running business tasks with observable execution
- Permissions, auditability, and multi-user collaboration
- Integration points for CRM and operational systems
Planned Google Cloud Usage
EigenInsight is designed to run on cloud infrastructure that can scale with document ingestion, retrieval, agent execution, and evaluation workloads. The planned Google Cloud deployment uses:
- Vertex AI and Gemini for agent reasoning, multimodal understanding, and evaluation workflows
- Cloud Run for API services, ingestion jobs, and long-running agent workers
- Cloud SQL or AlloyDB for tenant data, workflow state, and product metadata
- Cloud Storage for uploaded documents, parsed artifacts, and generated reports
- BigQuery for usage analytics, retrieval quality analysis, and evaluation traces
- Cloud Logging, Cloud Monitoring, and Secret Manager for observability and secure operations
These workloads are expected to grow with product trials, enterprise pilots, and larger private knowledge bases.